数据库种子数据
为本地和测试环境填充初始数据,确保可复现的环境配置。
什么是种子数据?
种子数据(Seed data)是指向数据库填充初始数据的过程,通常用于为测试和开发提供示例或默认记录。您可以使用此功能为本地开发、预发布和生产环境创建"可复现的环境"。
使用种子文件
每次运行 supabase start 或 supabase db reset 命令时都会执行种子文件。种子数据的填充操作会在所有数据库迁移完成后进行。最佳实践是种子文件中只包含数据插入语句,避免添加表结构定义语句。
默认情况下,如果没有提供特定配置,系统会查找符合 supabase/seed.sql 模式的种子文件。这保持了与早期版本的向后兼容性,早期版本中种子文件就放置在 supabase 文件夹中。
您可以在此文件中添加任何SQL语句。例如:
123456insert into countries (name, code)values ('United States', 'US'), ('Canada', 'CA'), ('Mexico', 'MX');如果您需要管理多个种子文件或跨不同文件夹组织它们,可以在 config.toml 中配置额外的路径或通配模式(详见下一章节)。
拆分种子文件
为了更好的模块化和可维护性,您可以将种子数据拆分为多个文件。例如,可以按表组织种子文件,包含诸如 countries.sql 和 cities.sql 等文件。在 config.toml 中配置如下:
123[db.seed]enabled = truesql_paths = ['./countries.sql', './cities.sql']或者要包含特定文件夹下的所有 .sql 文件,可以这样配置:
123[db.seed]enabled = truesql_paths = ['./seeds/*.sql']CLI 会按照 sql_paths 数组中声明的顺序处理种子文件。如果使用通配符模式匹配多个文件,这些文件将按字典序排序以确保执行顺序一致。此外:
- 模式匹配的基础文件夹是
supabase,因此./countries.sql会查找supabase/countries.sql - 被多个模式匹配的文件会被去重,防止重复播种
- 如果模式未匹配到任何文件,将记录警告以帮助排查潜在的配置问题
生成种子数据
您可以使用Snaplet为本地开发生成种子数据。
使用Snaplet需要先安装Node.js和npm。您可以通过在项目目录中运行npm init -y来添加Node.js到项目中。
如果是首次使用Snaplet生成项目数据,需要通过以下命令进行初始化设置:
1npx @snaplet/seed init该命令会分析您的数据库及其结构,然后生成一个JavaScript客户端,用于通过代码精确定义数据生成方式。init命令会生成一个配置文件seed.config.ts和一个示例脚本seed.ts作为起点。
在init过程中,如果您没有使用对象关系映射器(ORM)或您的ORM不在支持列表中,请选择node-postgres。
大多数情况下,您只需要为特定模式或表生成数据。这可以通过select参数定义。以下是一个seed.config.ts配置文件的示例:
1234567891011export default defineConfig({ adapter: async () => { const client = new Client({ connectionString: 'postgresql://postgres:postgres@localhost:54322/postgres', }) await client.connect() return new SeedPg(client) }, // 我们只想为public模式生成数据 select: ['!*', 'public.*'],})假设您有以下模式的数据库:
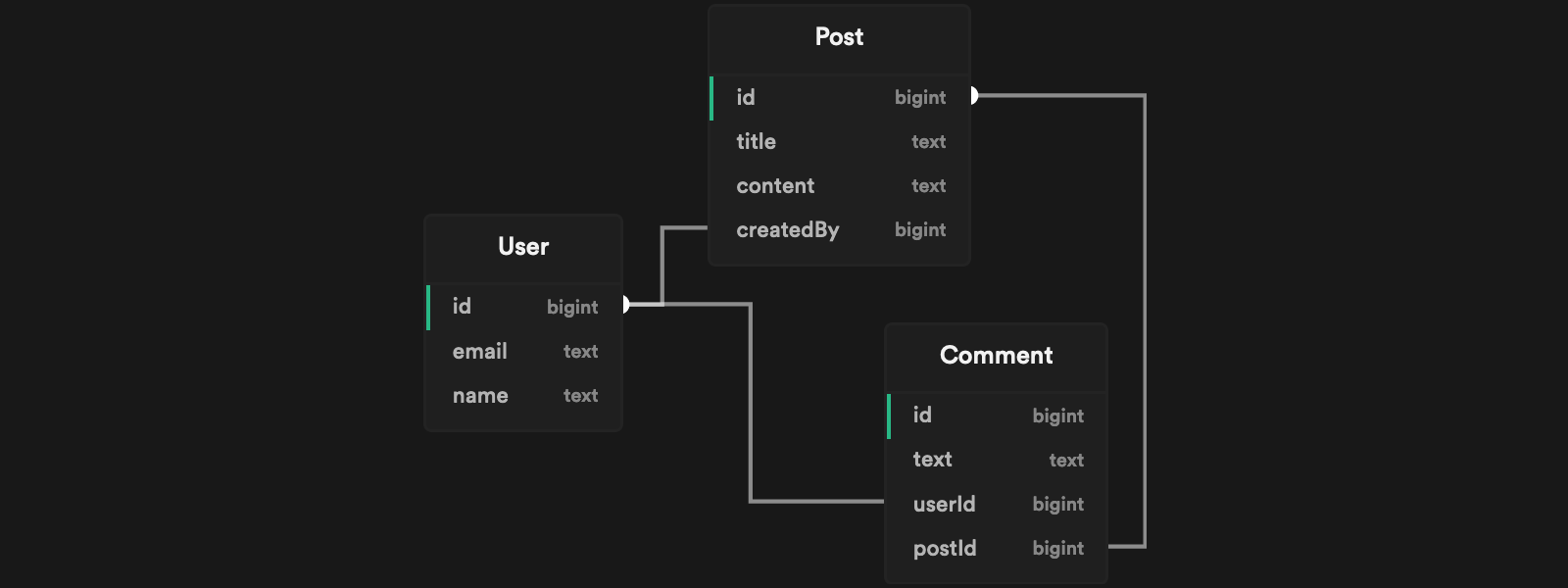
您可以使用Snaplet生成的seed.ts示例脚本来定义要生成的值。例如:
- 标题为
"There is a lot of snow around here!"的Post - 邮箱以
"@acme.org"结尾的Post.createdBy用户 - 来自三个不同用户的三条
Post.comments
1234567891011121314151617181920212223import { createSeedClient } from '@snaplet/seed'import { copycat } from '@snaplet/copycat'async function main() { const seed = await createSeedClient({ dryRun: true }) await seed.Post([ { title: 'There is a lot of snow around here!', createdBy: { email: (ctx) => copycat.email(ctx.seed, { domain: 'acme.org', }), }, Comment: (x) => x(3), }, ]) process.exit()}main()运行npx tsx seed.ts > supabase/seed.sql会在您的supabase/seed.sql文件中生成相关SQL语句:
123456789101112131415161718-- 邮箱以`"@acme.org"`结尾的`Post.createdBy`用户INSERT INTO "User" (name, email) VALUES ("John Snow", "snow@acme.org")--- 标题为`"There is a lot of snow around here!"`的`Post`INSERT INTO "Post" (title, content, createdBy) VALUES ( "There is a lot of snow around here!", "Lorem ipsum dolar", 1)--- 来自三个不同用户的三条`Post.Comment`INSERT INTO "User" (name, email) VALUES ("Stephanie Shadow", "shadow@domain.com")INSERT INTO "Comment" (text, userId, postId) VALUES ("I love cheese", 2, 1)INSERT INTO "User" (name, email) VALUES ("John Rambo", "rambo@trymore.dev")INSERT INTO "Comment" (text, userId, postId) VALUES ("Lorem ipsum dolar sit", 3, 1)INSERT INTO "User" (name, email) VALUES ("Steven Plank", "s@plank.org")INSERT INTO "Comment" (text, userId, postId) VALUES ("Actually, that's not correct...", 4, 1)当数据库结构发生变化时,您需要重新生成@snaplet/seed以保持与新结构同步。可以通过运行以下命令实现:
1npx @snaplet/seed sync您还可以使用大型语言模型来生成更真实的数据。要启用此功能,请在.env文件中设置以下环境变量之一:
12OPENAI_API_KEY=<your_openai_api_key>GROQ_API_KEY=<your_groq_api_key>设置环境变量后,运行以下命令同步并生成种子数据:
12npx @snaplet/seed syncnpx tsx seed.ts > supabase/seed.sql更多信息,请查看Snaplet的种子数据文档