核心概念
嵌入(Embeddings)是许多AI和向量应用的核心。本指南将介绍这些概念。如果您想立即开始使用,请参阅我们的生成嵌入指南。
什么是嵌入?
嵌入能够捕捉文本、图像、视频或其他类型信息的"相关性"。这种相关性最常用于:
- 搜索:搜索词与文本内容的相似度如何?
- 推荐:两个产品的相似度如何?
- 分类:如何对文本内容进行分类?
- 聚类:如何识别趋势?
让我们通过一个文本嵌入的例子来理解。假设有以下三个短语:
- "猫追逐老鼠"
- "小猫捕猎啮齿动物"
- "我喜欢火腿三明治"
您的任务是将含义相似的短语分组。对人类来说这很明显:短语1和2几乎相同,而短语3则含义完全不同。
尽管短语1和2相似,但它们没有共同的词汇(除了"the")。然而它们的含义几乎相同。我们如何让计算机理解这些是相同的呢?
人类语言
人类使用词语和符号来交流语言。但孤立的词语大多没有意义——我们需要借助共同的知识和经验才能理解它们。"你应该Google一下"这句话只有在您知道Google是一个搜索引擎且人们已将其用作动词时才有意义。
同样地,我们需要训练神经网络模型来理解人类语言。一个有效的模型应该基于数百万个不同的示例进行训练,以理解每个单词、短语、句子或段落在不同上下文中的可能含义。
那么这与嵌入有什么关系呢?
嵌入向量如何工作?
嵌入向量将离散信息(单词和符号)压缩为分布式连续值数据(向量)。如果我们把之前的短语绘制在图表上,可能会呈现如下效果:
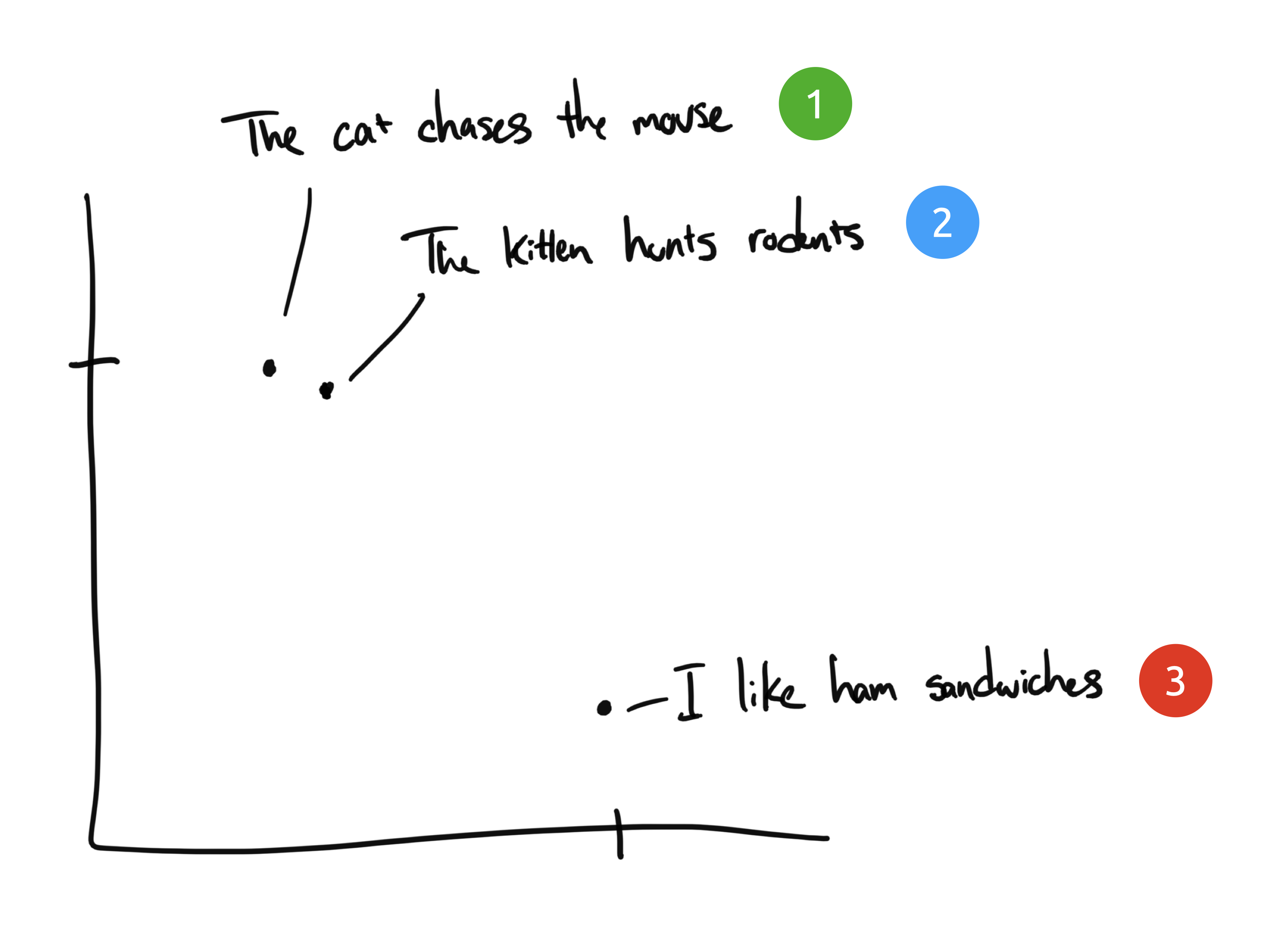
短语1和2会紧密地绘制在一起,因为它们的含义相似。而短语3则会位于较远的位置,因为它与前两者无关。如果加入第四个短语"Sally ate Swiss cheese",它可能会位于短语3(奶酪可以放在三明治上)和短语1(老鼠喜欢瑞士奶酪)之间的某个位置。
在这个示例中我们只有两个维度:X轴和Y轴。实际上,我们需要更多维度才能有效捕捉人类语言的复杂性。
使用嵌入向量
相比上面的二维示例,大多数嵌入模型会输出更多维度。例如开源模型gte-small会输出384个维度。
这有什么用?一旦我们为多个文本生成嵌入向量,就可以轻松通过余弦距离等向量数学运算计算它们的相似度。一个典型应用场景是搜索,流程可能如下:
- 预处理知识库并为每个页面生成嵌入向量
- 存储嵌入向量供后续引用
- 构建搜索页面获取用户输入
- 对用户输入生成一次性嵌入向量,并与预处理的嵌入向量进行相似度搜索
- 向用户返回最相似的页面