构建ChatGPT插件
使用Supabase作为ChatGPT插件的检索存储
ChatGPT 近期发布了插件功能,帮助 ChatGPT 获取最新信息、执行计算或使用第三方服务。如果您正在为 ChatGPT 构建插件,可能会需要从特定数据源回答问题。我们可以通过"检索插件"来实现这一需求,它允许 ChatGPT 从数据库中获取信息。
什么是 ChatGPT 检索插件?
检索插件是一个 Python 项目,旨在将外部数据注入 ChatGPT 对话中。它具有以下功能:
- 将文档分割成较小的片段
- 使用 OpenAI 的
text-embedding-ada-002模型将文本片段转换为向量嵌入 - 将这些向量嵌入存储到向量数据库中
- 当用户提问时,从向量数据库中查询相关文档
这使得 ChatGPT 能够动态地从您的数据源(如 PDF 文档、Confluence 或 Notion 知识库)中提取相关信息到对话中。
示例:与Postgres文档对话
让我们构建一个示例,可以"向ChatGPT提问"关于Postgres文档的问题。虽然ChatGPT已经了解Postgres文档(因为它是公开可用的),但这个简单示例展示了如何处理PDF文件。
该插件需要以下几个步骤:
- 下载Postgres文档PDF版本
- 将文档转换为嵌入式文本块并存储在Supabase中
- 本地运行我们的插件,以便能够询问关于Postgres文档的问题
我们将把Postgres文档保存在Postgres中,当用户提问时,ChatGPT会检索这些文档:
第一步:Fork ChatGPT检索插件仓库
将ChatGPT检索插件仓库Fork到您的GitHub账户,并克隆到本地机器。阅读README.md文件以了解项目结构。
第二步:安装依赖
选择您想要的数据存储提供程序,并从pyproject.toml中移除未使用的依赖项。本示例我们将使用Supabase。使用Poetry安装依赖:
1poetry install步骤3:创建Supabase项目
按照此指南的说明创建一个Supabase项目和数据库。导出检索插件运行所需的环境变量:
1234export OPENAI_API_KEY=<open_ai_api_key>export DATASTORE=supabaseexport SUPABASE_URL=<supabase_url>export SUPABASE_SERVICE_ROLE_KEY=<supabase_key>如果使用Postgres数据存储,则需要导出以下环境变量:
1234export OPENAI_API_KEY=<open_ai_api_key>export DATASTORE=postgresexport PG_HOST=<postgres_host_url>export PG_PASSWORD=<postgres_password>步骤4:本地运行Postgres
为了快速开始,您可以使用Supabase CLI在本地启动所有服务,因为它已经预装了pgvector。安装supabase-cli后,进入仓库中的examples/providers目录并运行:
1supabase start这将拉取所有Docker镜像并在您本地机器的Docker中运行Supabase技术栈。同时会自动应用所有必要的迁移来设置整个环境。之后您就可以像使用线上环境一样使用本地设置,只需导出环境变量并继续后续步骤。
使用supabase-cli不是必须的,您也可以使用任何其他包含pgvector的Docker镜像或托管版Postgres。只需确保运行来自examples/providers/supabase/migrations/20230414142107_init_pg_vector.sql的迁移即可。
步骤5:获取OpenAI API密钥
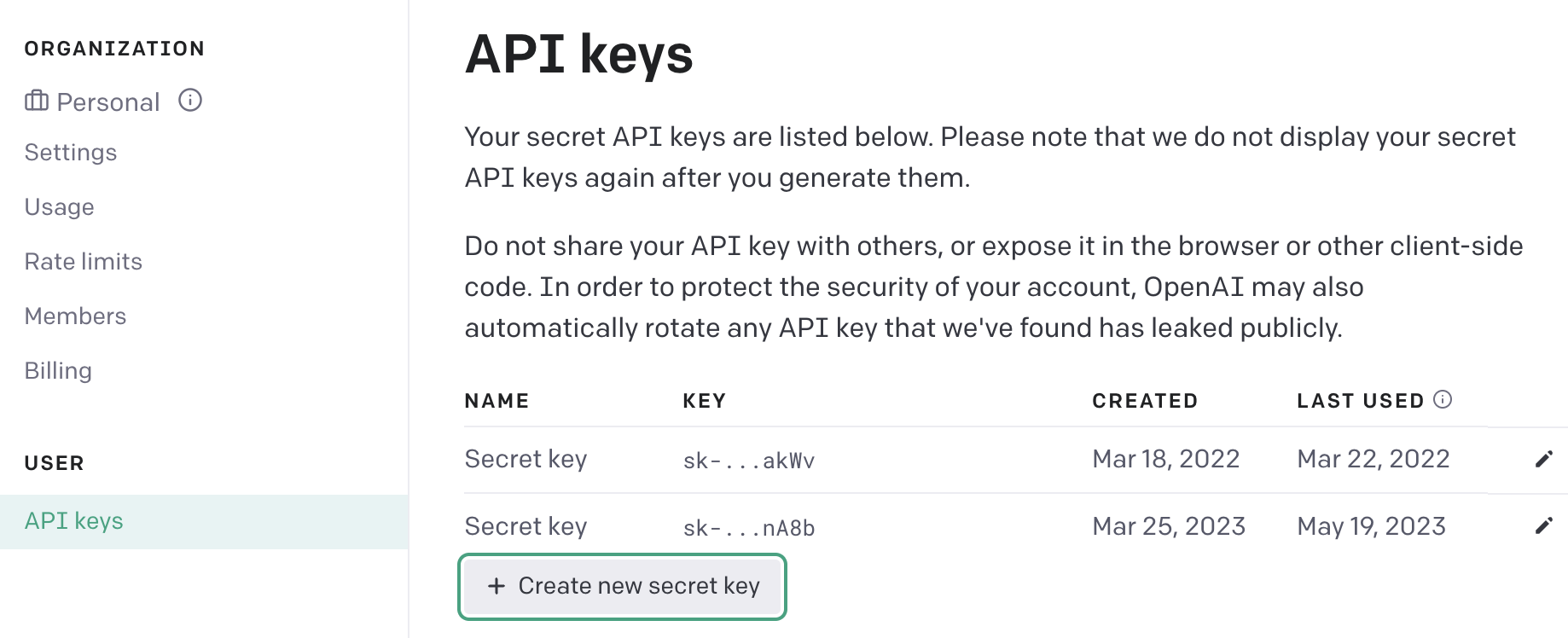
为了创建嵌入向量,插件需要使用OpenAI API和text-embedding-ada-002模型。每次我们向数据存储添加数据或尝试从中查询相关信息时,都会为插入的数据块或查询本身创建嵌入向量。要使此功能正常工作,我们需要导出OPENAI_API_KEY。如果您已有OpenAI账户,只需访问用户设置-API密钥并创建新的密钥。
步骤6:运行插件
执行以下命令来运行插件:
123456789poetry run dev# 输出INFO: 将监视以下目录的变更:['./chatgpt-retrieval-plugin']INFO: Uvicorn运行在 http://localhost:3333 (按CTRL+C退出)INFO: 已使用WatchFiles启动重载进程[87843]INFO: 已启动服务器进程[87849]INFO: 等待应用启动完成。INFO: 应用启动完成。插件将在您的本地主机上启动,默认端口为:3333。
步骤6:向数据存储填充数据
在本示例中,我们将上传Postgres文档到数据存储中。请下载Postgres文档并使用/upsert-file端点进行上传:
1curl -X POST -F \\"file=@./postgresql-15-US.pdf\\" <http://localhost:3333/upsert-file>该插件会自动将您的数据和文档分割成较小的块。您可以使用Supabase仪表板或任何您喜欢的SQL客户端查看这些数据块。完整的Postgres文档共生成7,904条记录,虽然数量不大,但我们可以尝试为embedding列添加索引来略微提升速度。为此,您需要运行以下SQL命令:
123create index on documentsusing hnsw (embedding vector_ip_ops)with (lists = 10);这将为内积距离函数创建索引。需要注意的是这是一个近似索引,它会将精确最近邻搜索逻辑改为近似最近邻搜索。
我们使用lists = 10是因为作为一般准则,当表中记录少于100万条时,您应该按照行数/1000的公式来寻找最优的lists常数值。
步骤7:在ChatGPT中使用我们的插件
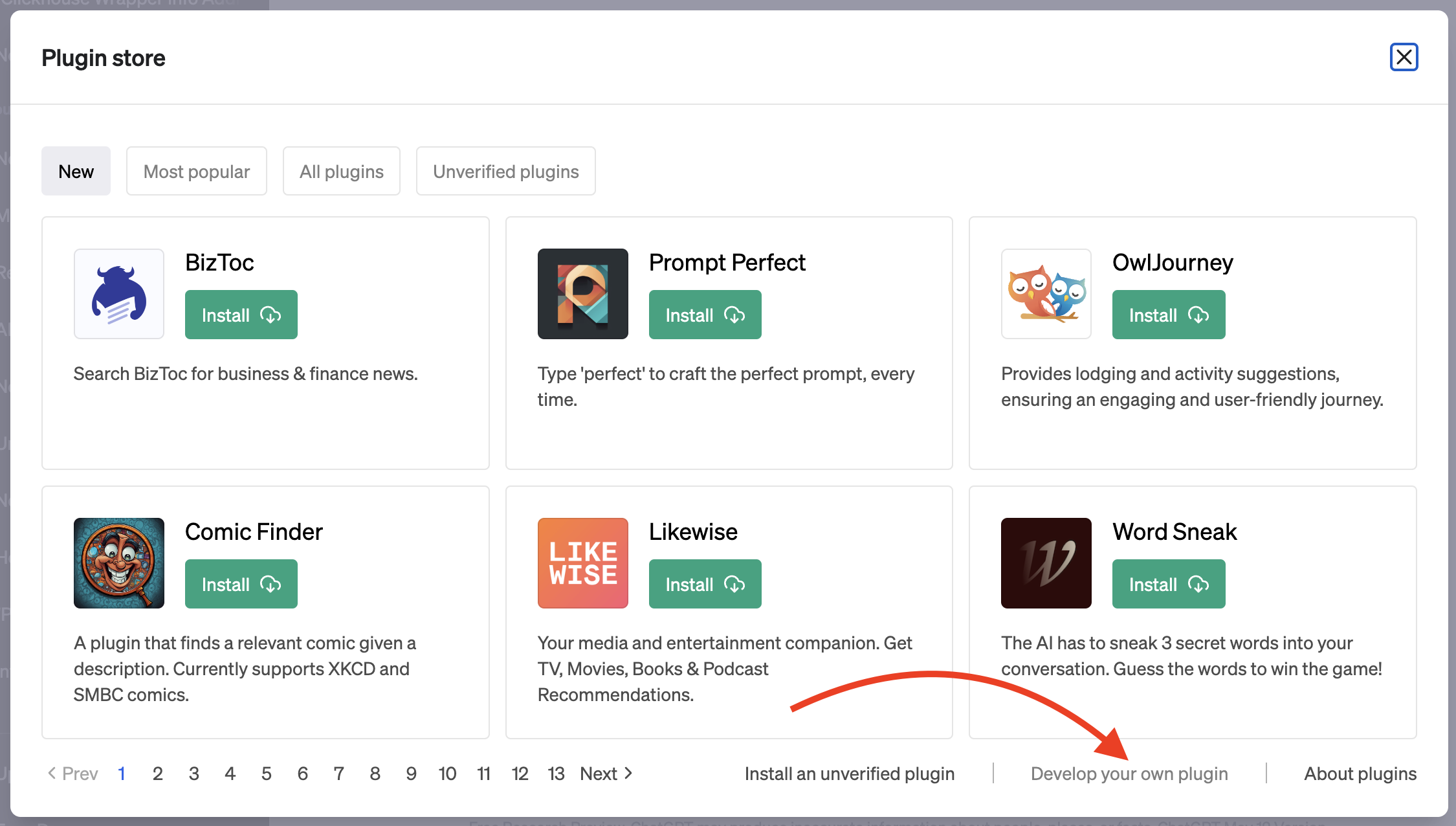
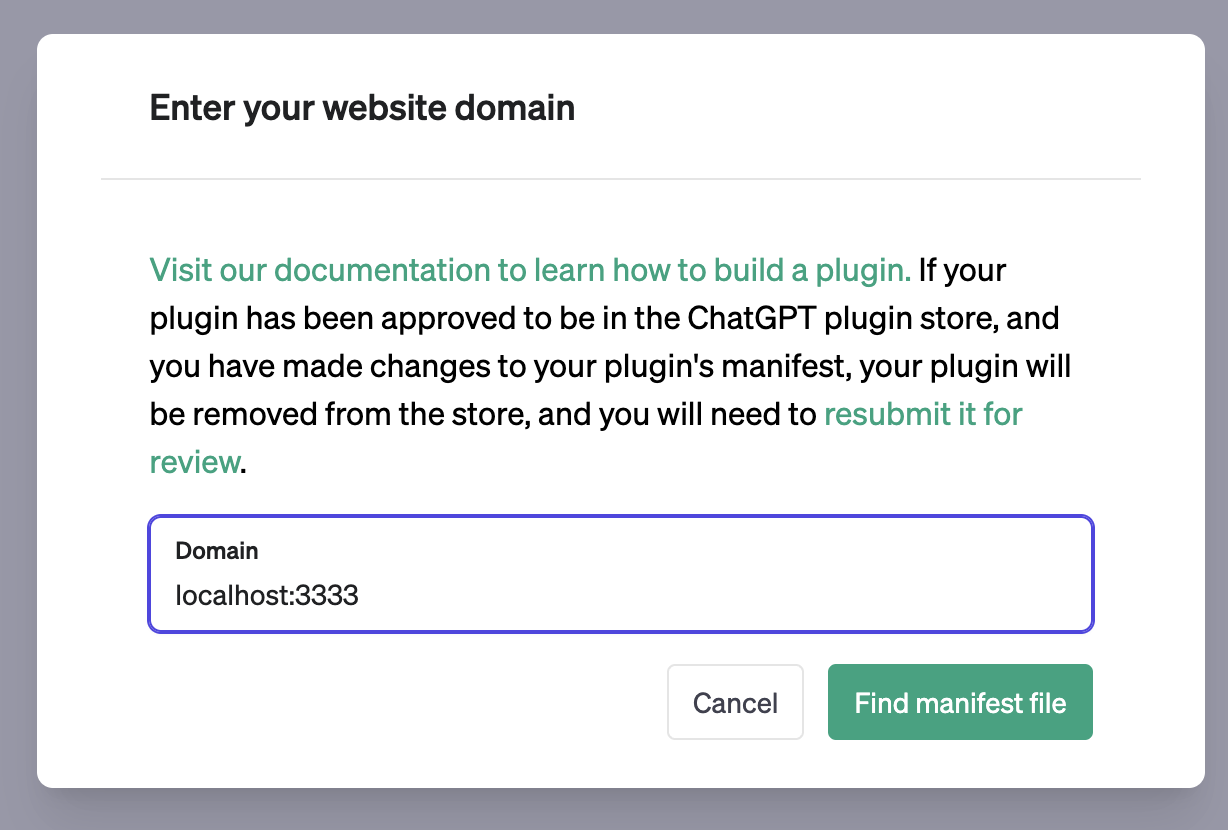
要将我们的插件集成到ChatGPT中,请在ChatGPT仪表板中注册插件。假设您已获得ChatGPT插件和插件开发权限,在新聊天中选择"Plugins"模型,然后点击"Plugin store"并选择"Develop your own plugin"。在域名输入框中输入localhost:3333,您的插件就会成为ChatGPT的一部分。
现在您可以询问关于Postgres的问题,并获得来自文档的答案。
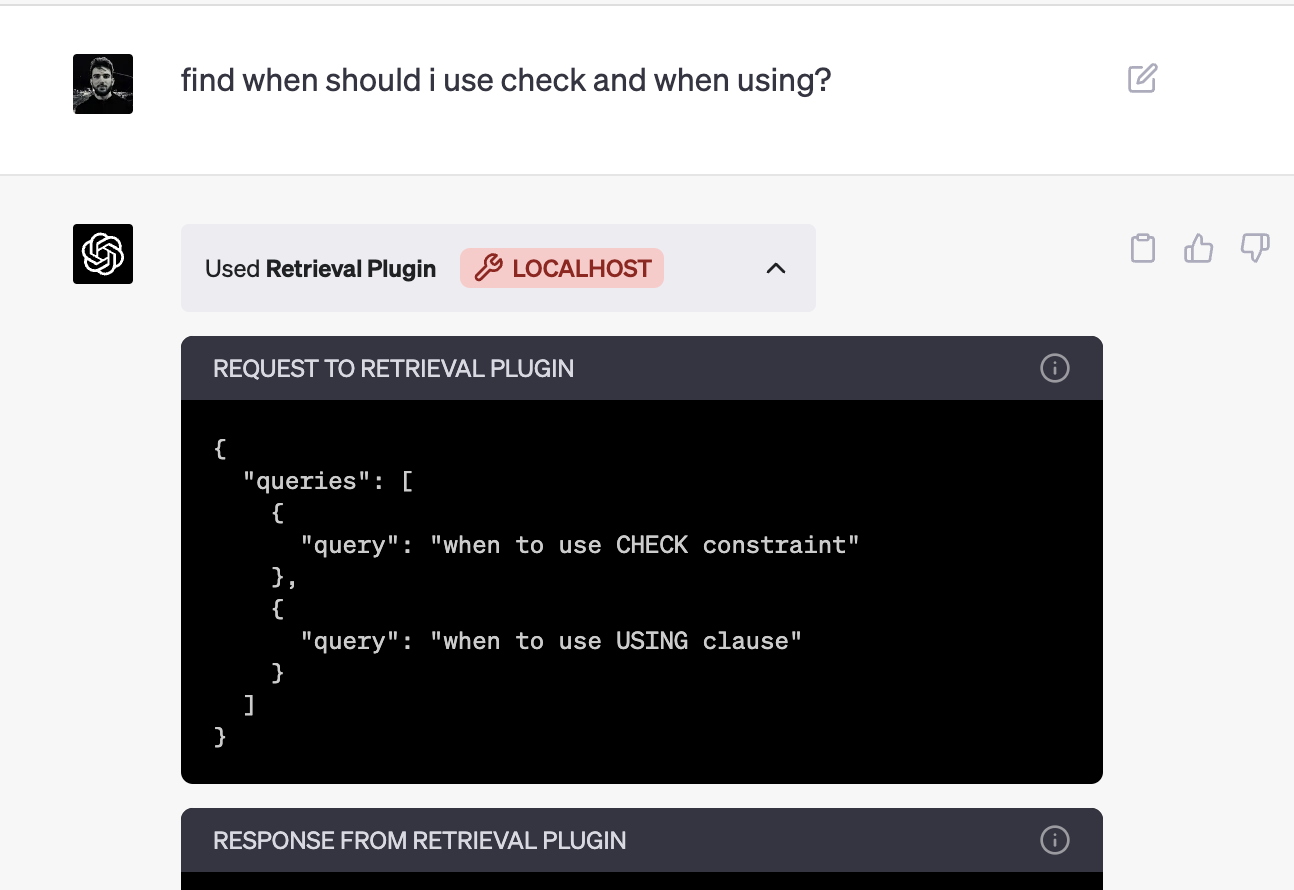
让我们试一下:让ChatGPT查询何时使用check和何时使用using。您将能看到发送给我们插件的查询内容以及插件的响应。
当ChatGPT收到插件的响应后,它会根据文档数据回答您的问题。

相关资源
- ChatGPT检索插件: github.com/openai/chatgpt-retrieval-plugin
- ChatGPT插件: 官方文档